Research Highlights
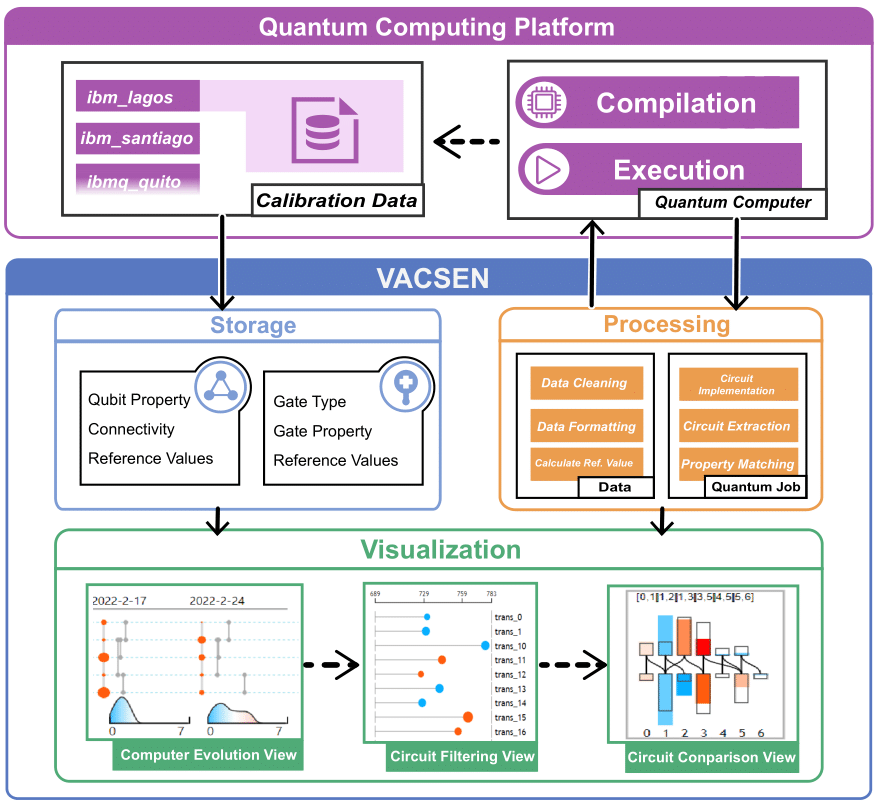
Noise Characterization, Visualization, Modeling and Noise Mitigantion in Near Intermediate Scale Quantum Computers
The growth of the need for quantum computers in many domains such as machine learning, numerical scientific simulation and finance has necessitated that quantum computers produce stable results. However, mitigating the impact of the noise inside each quantum device presents an immediate challenge. In this project, we investigate the noise characterization over the time, analyze the temporal model of the noise, visualize the dynamic changes through building visualization system, and noise prediction to mitigate the impact of the noise to the use of NISQ machines.
Publications: TVCG’23, EuroVIS’23, IEEE VIS’22, TVCG’22, DSN’22, QCE’22, DSB-W’21, SELSE’21
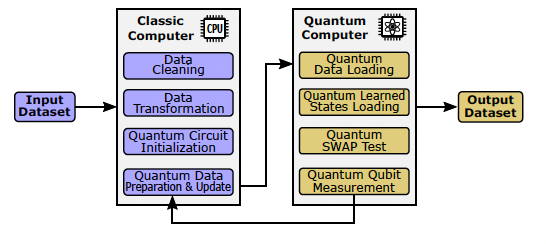
Quantum Machine Learning Model Design and Optimization
In the past decade, remarkable progress has been achieved in deep learning related systems and applications. In the post Moore’s Law era, however, the limit of semiconductor fabrication technology along with the increasing data size have slowed down the development of learning algorithms. In parallel, the fast development of quantum computing has pushed it to the new ear. Google illustrates quantum supremacy by completing a specific task (random sampling problem), in 200 seconds, which is impracticable for the largest classical computers. Due to the limitless potential, quantum based learning is an area of interest, in hopes that certain systems might offer a quantum speedup. In this research, we investigate the new quantum-classic hybrid models that encodes the data with a minimium number of qubits.
Publications: QCE’22, DSB-W’21, SELSE’21
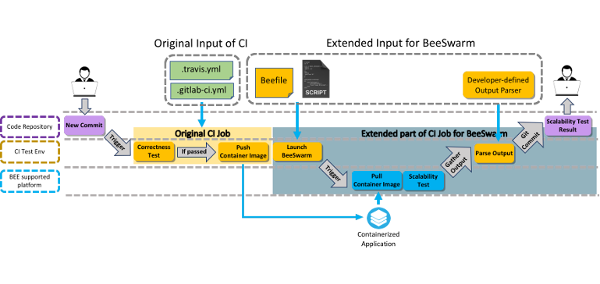
HPC Container based Workflow Systems for HPC-Cloud Hybrid Systems
In this project, we propose a workflow orchestration system that is able to run workflows on both HPC systems and in the cloud using HPC containers. Most existing workflow orchestration systems are only able to run workflows on one system at a time, and thus may be unable to run workflows that require more resources than what some platforms provide, and may also be unable to handle validation and fault tolerance requirements. Users may have access to a number of different systems, perhaps a mix of HPC systems and private and public clouds, but currently are only able to utilize one system at a time for running complex workflows. Utilizing HPC containers, such as Charliecloud, and a subset of the Common Workflow Language (CWL) for representing workflows, we extend the BEE Orchestration System to allow for possible scheduling of very complex workflows across resources. BEE is meant to be run at the user level and to make use of existing infrastructure, such as Slurm. BEE is designed to focus on the requirements of specific users and their workflows and should take into account costs, deadline requirements, and other user-level factors. We design and implement a scheduling component and a component for interacting with OpenStack-based HPC clusters and Google Compute Engine clouds to allow for communication between any combination of Cloud and HPC components. We demonstrate how BEE orchestrates workflows across systems, making it possible to run complex scientific applications across all systems that are available to a user.
Publications: HiPC’21, ASE’21, IEEE BigData’18, ICDCS’18
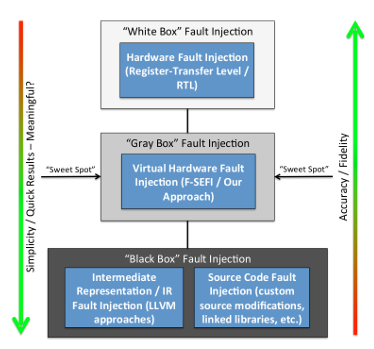
Parallel Fine-grained Soft Error Fault Injection and HPC Application Soft Error Vulnerability Analysis
Future exascale application programmers and users have a need to quantity an application’s resilience and vulnerability to soft errors before running their codes on production supercomputers due to the cost of failures and hazards from silent data corruption. Barring a deep understanding of the resiliency of a particular application, vulnerability evaluation is commonly done through fault injection tools at either the software or hardware level. Hardware fault injection, while most realistic, is relegated to customized vendor chips and usually applications cannot be evaluated at scale. Software fault injection can be done more practically and efficiently and is the approach that many researchers use as a reasonable approximation. With a sufficiently sophisticated software fault injection framework, an application can be studied to see how it would handle many of the errors that manifest at the application level. Using such a tool, a developer can progressively improve the resilience at targeted locations they believe are important for their target hardware.
Publications: IPDPS’14, ISSRE’14, Cluster’15, SIMUTOOL’16 PPoPP’17, EDCC’17, ICPP’18, DSN’20
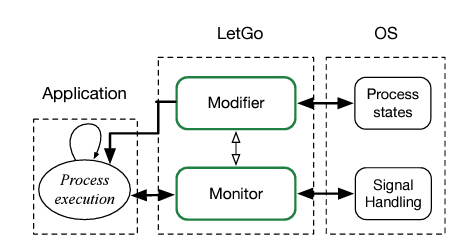
Application Level Failure Management and Error Mitigation
Requirements for reliability, low power consumption, and performance place complex and conflicting demands on the design of high-performance computing (HPC) systems. Fault-tolerance techniques such as checkpoint/restart (C/R) protect HPC applications against hardware faults. These techniques, however, have non-negligible overheads, particularly when the fault rate exposed by the hardware is high: it is estimated that in future HPC systems, up to 60% of the computational cycles/power will be used for fault tolerance. To mitigate the overall overhead of fault-tolerance techniques, we propose LetGo, an approach that attempts to continue the execution of an HPC application when crashes would otherwise occur. Our hypothesis is that a class of HPC applications has good enough intrinsic fault tolerance so that it’s possible to re-purpose the default mechanism that terminates an application once a crash-causing error is signaled, and instead attempt to repair the corrupted application state, and continue the application execution. This project explores this hypothesis and quantifies the impact of using this observation in the context of checkpoint/restart (C/R) mechanisms.
Publications: HPDC’17,SC’18, SC’19, ICS’19
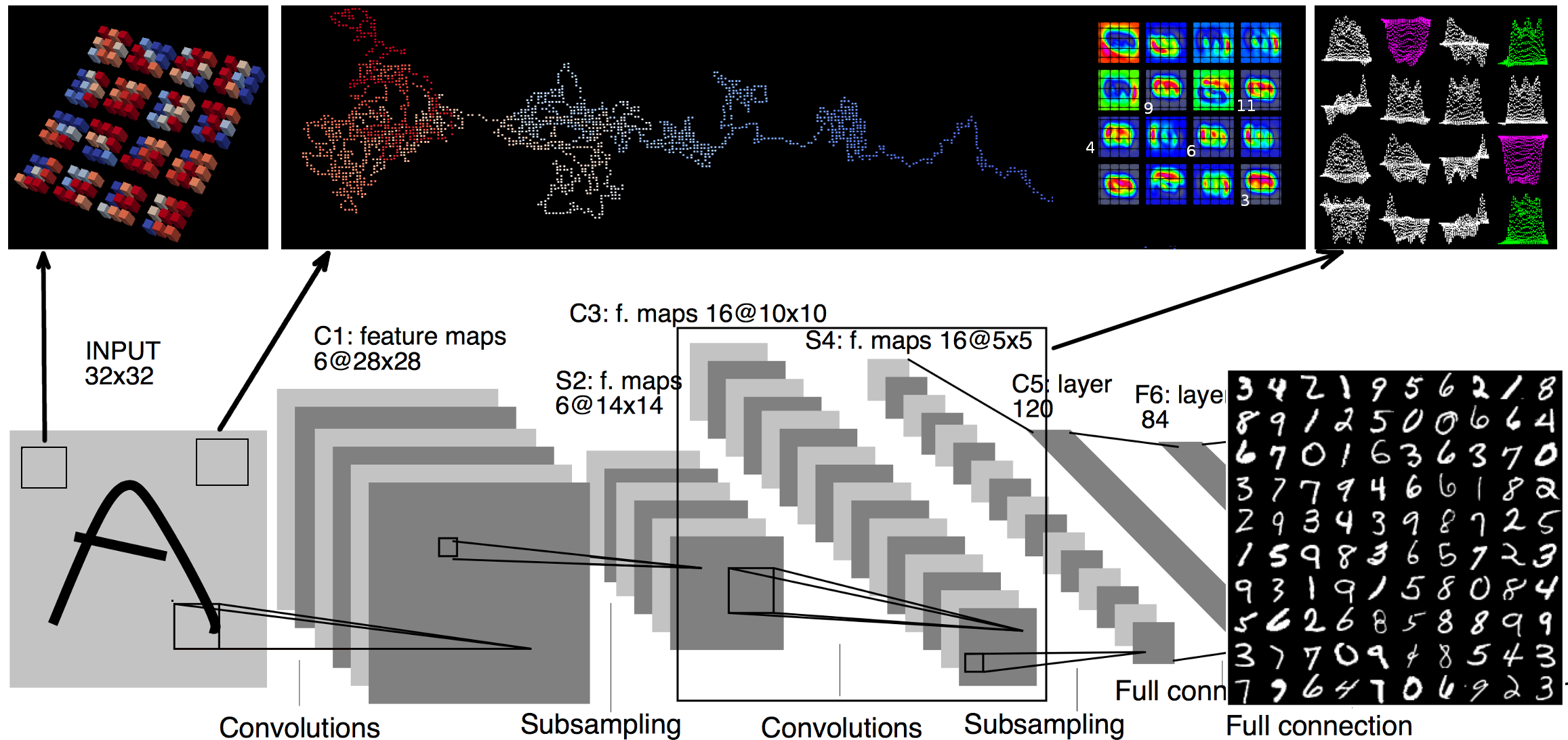
Visualization of Convolutional Neural Networks
Convolutional Neural Networks(CNNs) are complex systems. They are trained so they can adapt their internal connections to recognize images, texts and more. It is both interesting and helpful to visualize the dynamics within such deep artificial neural networks so that people can understand how these artificial networks are learning and making predictions. In the field of scientific simulations, visualization tools like Paraview have long been utilized to provide insights and understandings. We present in situ TensorView to visualize the training and functioning of CNNs as if they are systems of scientific simulations. In situ TensorView is a loosely coupled in situ visualization open framework that provides multiple viewers to help users to visualize and understand their networks. It leverages the capability of co-processing from Paraview to provide real-time visualization during training and predicting phases. This avoid heavy I/O overhead for visualizing large dynamic systems. Only a small number of lines of codes are injected in TensorFlow framework. The visualization can provide guidance to adjust the architecture of networks, or compress the pre-trained networks. We showcase visualizing the training of LeNet-5 and VGG16 using in situ TensorView.